Common crawl Sampling
29 Jul 2015 . Common crawl . Comments
A WARC file containing a sample of the Common crawl dataset of may (CC-MAIN-2015-22) was created using the common crawl index. Both sampling process and WARC creation process were run on a Amazon EC2 instance to improve the performance by taking advantage of the data transfer speed between S3 and EC2 Amazon infrastructures.
##Common crawl Index
Actually the sample is done from the index. By randomly retrieving index records and adding them into a file. Later this sample index is used to retrieve the records from the common crawl corpus.
The common crawl Index is generated per each common crawl data set(collection) which are generated in a monthly basis and the format of the index is called ZipNum Sharded CDX.
###Structure
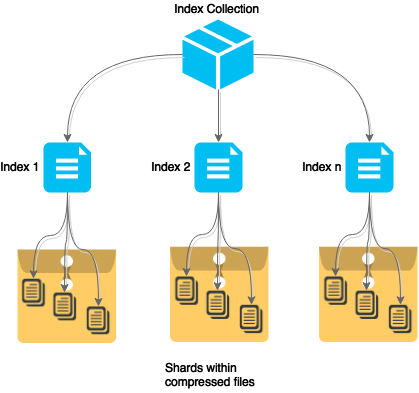
The index use the ZipNum Sharded CDX format which divides the complete index into several blocks(called shards) of indexes(commonly 3000 records). These shards are spread over multiple compressed files (part-file). For each of these part-files exists a “second index” that contains the start offset and length of every block.
###Common crawl Sampling algorithm
The below algorithm shows how the sample is built from a Common crawl collection. Starts by randomly distributing the numbers of records to be retrieved per shard index file. Then for every file, the similar procedure is done assigning how many records will be retrieved per shard. For example if a index file was assigned to retrieve 10 records, these 10 records will be randomly assigned to its shards, and then the records are taken randomly from the shards.
SET i=0
INIT all shardIndexFile.recordsToRetrieve = 0 //shard index files number of records to retrieve to zero
WHILE i <= sampleSize
SET shardIndexFile = pick a random shard Index file from the Index Collection
INCREMENT shardIndexFile.recordsToRetrieve by one
INCREMENT i by one
ENDWHILE
FOR each shardIndexFile in Index Collection
SET i=0
INIT all shard.recordsToRetrieve = 0
WHILE i <= shardIndexFile.recordsToRetrieve
SET shard = pick a random shard from the shard Index file
INCREMENT shard.recordsToRetrieve by one
INCREMENT i by one
ENDWHILE
SET records = GET random records from shard. The number of records to retrieve is the value of shard.recordsToRetrieve.
ADD records to sample
END FOR
WRITE sample records to file
Finally all these indexes records are concatenated into a plain text file.
##Creating the WARC file
The file with the indexes created before contains the location, offset and length of WARC records. By iterating over these indexes the records are obtained and concatenated in a new compressed WARC file that contains the sample.
public static void obtainCommonCrawlRecords(Path cdxFile, Path outputFile,AmazonS3Client s3Client, String bucket) throws IOException {
int totalLines = countLines(cdxFile);
OutputStream out;
try {
out = Files.newOutputStream(outputFile);
try {
GZIPMemberWriter writer = new GZIPMemberWriter(out);
try (BufferedReader reader = Files.newBufferedReader(cdxFile,
Charset.forName("UTF-8"))) {
String line = null;
while ((line = reader.readLine()) != null) {
CCIndexRecord index = new CCIndexRecord(line);
long offset = index.getOffset();
long length = index.getLength();
String key = index.getKey();
String record = getChunk3S(bucket, key, offset, length,
s3Client);
InputStream in = IOUtils.toInputStream(record, "UTF-8");
writer.write(in);
System.out.println("Records remaining: "+--totalLines);
}
}
} finally {
out.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}